
发布日期:2026-05-17 06:06 点击次数:126

梦晨 发自 凹非寺Kaiyun·官方网站
量子位 | 公众号 QbitAIAI再也不是“回合制”了。
Thinking Machines Lab(以下简称TML)发布首个模子,让实时交互材干成为模子原生材干。
蚁集创举东说念主翁荔出镜演示。
从“东说念主说完→AI答→东说念主再说→AI再答”,形成了“东说念主和AI皆不错随时插嘴,说结束代码也写结束”。
音频和代码同期输出,说结束活也干结束。
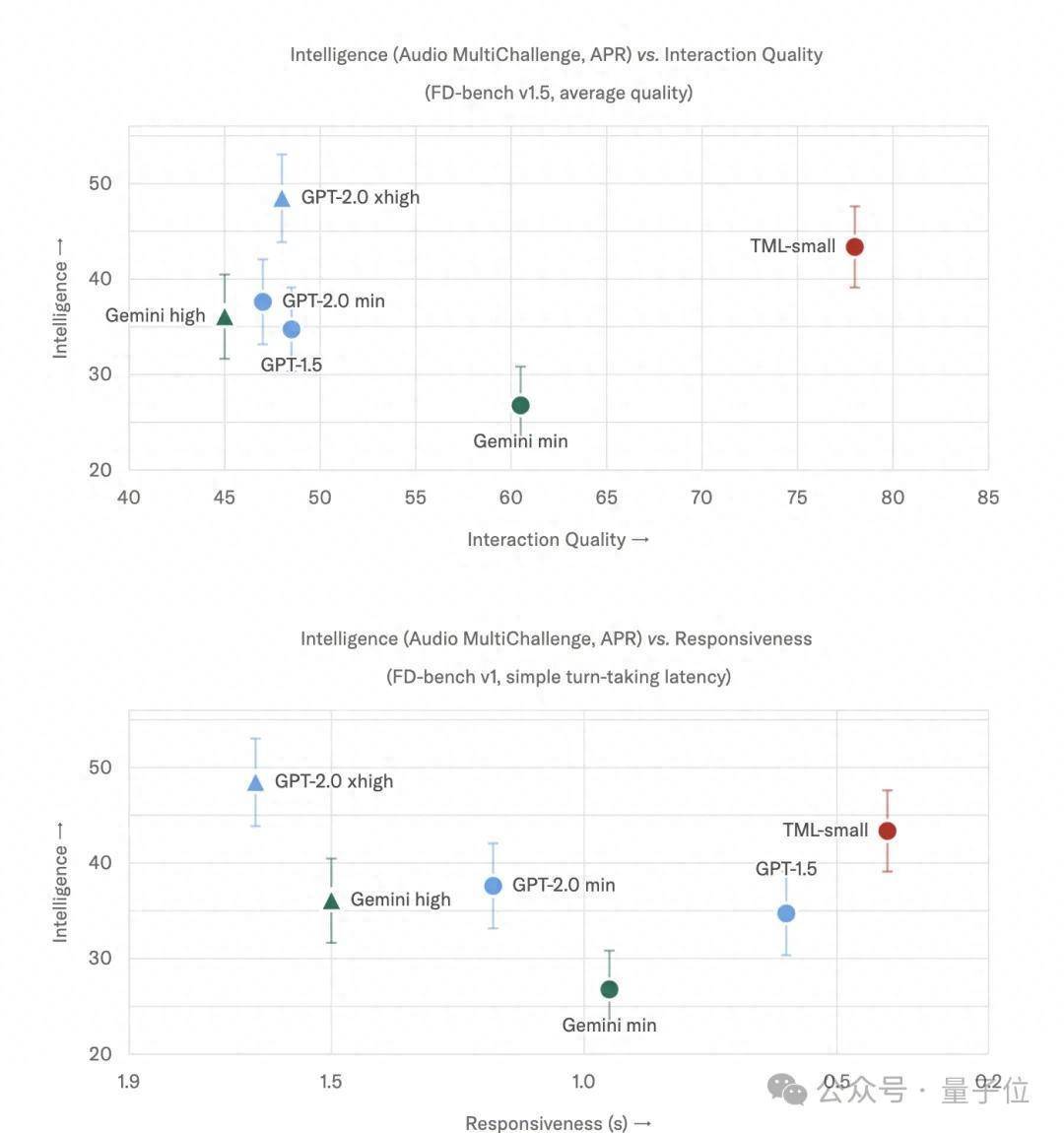
在测试限制上,反应蔓延比GPT-realtime-2.0快4倍,交互质地测评高出GPT-realtime-2.0,只在模子才略上还不如GPT-2.0 xhigh格式。
在几个月里,团队锻真金不怕火了12个版块,留住了137页的锻真金不怕火日记。
今天,这家由OpenAI前CTO创办的践诺室,终于交卷首个模子TML-Interaction-Small。
也让外界知说念了“Thinking Machines”的委果含义:
把语音助手、视频贯串和Agent互助放到统一个框架里处理。
增多东说念主机交互带宽,模子边听边说边思委果使命里,许多需求根柢不可能一启动就澈底证据晰。
你可能讲到一半思改场合,看到限制后思补条目,发现模子误会了一个词,大略只思在缺陷节点插一句“不是这个敬爱”。
要是东说念主类之间只可用邮件相通,后果就太低了。
现时大多数AI系统的基本节律,亦然邮件式的“回合制”。
用户输入时,模子等着。模子生成时,它对新信息的感知又会冻结。除非被打断,不然它不知说念你正在作念什么、看到什么、纠结什么。
这就把东说念主和AI的互助压在一个很窄的通说念里,东说念主的学问、意图、判断,被这条邮件式窄带宽漏掉了泰半。
同期,回合制的AI系统不维持精准的时间测度或同步语音。
比如这些任务现存AI就澈底无法回答:“我跑一英里花了多永劫期?”、“请蜕变我的发音伪善”或“我写这个函数花了多永劫期?
要处理这些问题,TML让AI在职何模态上皆能实时交互,让接口去适合东说念主,而不是反过来让东说念主去迁就接口。
现时多数AI模子处理交互问题,是外挂一层harness,拼接 VAD(语音行动检测)、turn-detection、TTS这些组件,模拟出实时感。
TML搬出了新的“Bitter Lesson”:
这些拼接出来的系统,长久看会被通用材干的彭胀给追平以致超过。
思让交互材干跟着智能一齐scale,交互材干就必须作念进模子本人。那么,“交互作念进模子”具体是何如达成的?
前台实时反应,后台干重活这套交互模子最缺陷的机制,是把连气儿音频、视频、文本皆切成200ms的“微回合”,
让输入和输出在时间上交错输入统一个模子。
千里默、访佛语言、用户自我修正、视觉变化皆不再是外部气象,而是模子能径直学习和反应的转折文。
旧措施:模子等竣工用户轮次,再生成竣工报告;实时感主要靠外部组件判断谁该语言。
新措施:每 200ms 处理输入,也生成输出,输入输出像流相通交错。
举座架构是双模子协同。
前台模子抓续袭取新输入、报告追问、防守转折文;后台模子异步跑长推理、器具调用和Agent使命流。
碰到不成即时算出来的任务,Interaction Model 把竣工对话转折文打包丢给后台。
后台一边算,限制一边流式回传过来,前台找个合乎的时机插进对话里。锻真金不怕火阶段的中枢措施是encoder-free early fusion。
大多数全模态模子要么训独处的encoder(类Whisper),要么训独处的decoder(类TTS),
TML的作念法:
音频编码不必一个广漠的独处encoder,而是用dMel加一个轻量embedding层,图像切成 40x40的patch由hMLP编码,音频输出用flow head解码。
整个这些组件,跟Transformer一齐重新共同锻真金不怕火,在锻真金不怕火阶段就让它们分享一个实时互动语境。
200ms的反应速率也带来工程压力。
每200ms一次央求,意味着无数小prefill和小decode。传统LLM推理库并不擅长这种高频小块使命,支拨可能被央求经管、内存分拨、元数据野心吃掉。
TML又作念了一层streaming sessions。
客户端仍然按 200ms chunk 发送央求,就业端则把这些 chunk 追加到 GPU memory 里的 persistent sequence 中,幸免反复重分拨。发布方还称,关连功能的也曾发布到SGLang。
从新顽强Thinking Machines Lab曩昔说到Thinking Machines Lab这家公司,最容易被记取的标签是再0居品、0收入阶段,就拿到高融资。
Mira Murati从OpenAI离开后创办TML,很快完成约20亿好意思元种子轮融资,估值达到120亿好意思元。
这个数字太驻扎,但很长一段时间人人皆不知说念这家公司到底要作念什么?
自后的陈迹也有点散布。
一边是东说念主。
到2026年,TML约140 东说念主,Meta是它挖东说念主最多的起头。从CTO Soumith Chintala,到参与过Segment Anything关连使命的 Piotr Dollar,再到多位 FAIR、多模态、LLM 锻真金不怕火布景的盘问员,皆加入了TML。
一边是算力。
2026年3月,TML和英伟达秘书长久合作,贪图通过Vera Rubin系统取得至少1GW算力,英伟达也参与了TML的融资。
2026年4月22日,TML和谷歌签下单个位数十亿好意思元级别的云野心公约,将取得基于英伟达 GB300 的系统,用于模子锻真金不怕火和部署。
但很长一段时间,他们的居品就只消一个锻真金不怕火基础缺陷Tinker。
此次交互模子,TML第一次把我方的技巧阶梯竣工摆出来:把AI的交互范式从居品外壳,推动到模子实质。
以前的行动也皆看清了:
200ms需要低蔓延推理系统;前台交互模子和后台模子需要沉着的锻真金不怕火、息争和器具链;多模态实时输入输出需要更强的锻真金不怕火和部署底座;更大限制模子要在这种实时设定里跑起来,更离不开GB300、Vera Rubin这类算力。TML 思赌的,是下一个东说念主机互助界面。
本年新加入团队的斯坦福博士Zitong Yang,还设思过把整个这个词大模子预锻真金不怕火数据重写成智能体轨迹。
此次发布的TML-Interaction-Small还仅仅第一步。
按照发布方说法,它是276B 参数 MoE、12B激活参数,现时更大限制的预锻真金不怕火模子还无法胜任实时交互任务。
更大限制的模子,贪图在本年晚些时候发布。
参考联贯:
[1]https://thinkingmachines.ai/blog/interaction-models/[2]https://x.com/thinkymachines/status/2053938906689884279